
Die Entwicklung der Daten-Pipeline
Für die modernen datenintensiven Anwendungen ist die Daten-Pipeline der zentrale Pfeiler. Im ersten Beitrag dieser Serie werfen wir einen Blick auf die Geschichte der Daten-Pipeline und wie sich die damit verbundenen Technologien im Laufe der Zeit entwickelt haben. Nachfolgend erfahren Sie, wie einige dieser Systeme bei Barracuda zum Einsatz kommen und was bei der Evaluierung von Komponenten der Daten-Pipeline zu beachten ist. Desweiteren führen wir einige Beispiele neuartiger Anwendungen an, die Ihnen den Einstieg in die Entwicklung und die Bereitstellung dieser Technologien erleichtern.
MapReduce
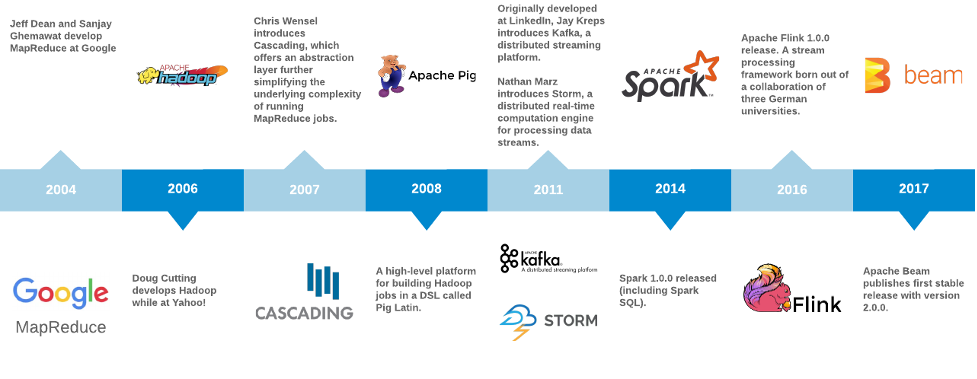
Im Jahr 2004 veröffentlichten Jeff Dean und Sanjay Ghemawat von Google MapReduce: Simplified Data Processing on Large Clusters. Sie beschrieben MapReduce wie folgt:
„[…] ein Programmiermodell samt Implementierung zur Verarbeitung und Erzeugung großer Datensätze.“ Benutzer legen sowohl eine Map-Funktion fest, die ein Schlüssel/Wert-Paar verarbeitet, um eine Reihe von Zwischen-Schlüssel/Wert-Paaren zu generieren, als auch eine Reduce-Funktion, die alle mit demselben Zwischenschlüssel verknüpften Zwischenwerte zusammenführt.“Mit dem MapReduce-Modell konnten sie den parallelen Workload zur Generierung des Google Web-Index vereinfachen. Dieser Workload wurde einem Knoten-Cluster zugewiesen und bot eine Skalierbarkeit, die mit dem Web-Wachstum Schritt halten kann.
Ein wichtiger Aspekt von MapReduce ist, wie und wo Daten im Cluster gespeichert werden. Bei Google wurde dies als Google File System (GFS) bezeichnet. Eine Open-Source-Implementierung von GFS aus dem Apache-Nutch-Projekt wurde letztlich in eine Open-Source-Alternative zu MapReduce namens „Hadoop“ umgewandelt. Hadoop ist 2006 aus Yahoo! hervorgegangen. (Der Name Hadoop geht übrigens auf einen Spielzeugelefanten zurück, der dem Sohn von Doug Cutting gehörte.)
Apache Hadoop: Eine Open-Source-Implementierung von MapReduce
Apache Spark: Eine einheitliche Analyse-Engine für die Verarbeitung großer Datenmengen
Im Jahr 2009 begann Matei Zaharia mit der Entwicklung von Spark im AMPLab der University of California in Berkeley. Sein Team veröffentlichte Spark: Cluster Computing with Working Sets im Jahr 2010, das eine Methode zur Wiederverwendung einer Arbeitsmenge von Daten über mehrere parallele Operationen hinweg beschreibt, und veröffentlichte die erste öffentliche Version im März desselben Jahres. Ein Folgepapier von 2012 mit dem Titel Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing wurde auf dem USENIX Symposium on Networked Systems Design and Implementation als Best Paper ausgezeichnet. In dieser Arbeit wird ein neuartiger Ansatz namens Resilient Distributed Datasets (RDDs) beschrieben, mit dem Programmierer In-Memory-Berechnungen nutzen können, um Größenordnung-Leistungssteigerungen für iterative Algorithmen wie PageRank oder maschinelles Lernen für dieselbe Art von Jobs zu erreichen, die auf Hadoop basieren.
Neben den Leistungsverbesserungen für iterative Algorithmen war die Fähigkeit, interaktive Abfragen durchzuführen, eine weitere bedeutende Innovation von Spark. Spark nutzt einen interaktiven Scala-Interpreter, der es Datenforschern ermöglicht, Schnittstellen zum Cluster einzurichten und viel unkomplizierter mit großen Datensätzen zu experimentieren, als das bisher möglich war. Zuvor musste ein Hadoop-Job erst kompiliert und eingereicht werden und anschließend wartete man auf die Ergebnisse.
Ein Problem blieb jedoch bestehen — die Eingabe in diese Hadoop- oder Spark-Jobs berücksichtigt nur Daten aus einer begrenzten Quelle (es werden keine neu eingehenden Daten während der Laufzeit des Jobs berücksichtigt). Der Job zielt auf eine Eingabequelle ab; bestimmt, wie der Job in parallelisierbare Datenblöcke oder Aufgaben zerlegt werden soll; führt die Aufgaben im gesamten Cluster gleichzeitig aus; und kombiniert schließlich die Ergebnisse und speichert die Ausgabe an irgendeinem Ort. Dieses Framework bewährte sich hervorragend bei der Generierung von PageRank-Indizes oder bei einer logistischen Regression. Für eine große Anzahl anderer Jobs, die es mit Daten aus einer unbegrenzten oder Streaming-Quelle zu tun hatten, wie z. B. Clickstream-Analysen oder Betrugsbekämpfungsmaßnahmen, war dies jedoch das falsche Framework.
Apache Kafka: Eine dezentrale Streaming-Plattform
Im Jahr 2010 übernahm das Engineering-Team von LinkedIn die Aufgabe, die Grundlagen des beliebten sozialen Karrierenetzwerks [A Brief History of Kafka, LinkedIn's Messaging Platform] neu zu gestalten. Wie viele Websites wechselte LinkedIn von einer monolithischen Architektur zu einer Architektur mit vernetzten Microservices. Die Einführung einer neuen Architektur basierend auf einer universellen Pipeline, die auf einem dezentralen Commit-Log namens Kafka aufgebaut war, ermöglichte LinkedIn die Verarbeitung von Event-Streams nahezu in Echtzeit und in beachtlichem Umfang. LinkedIn-Chefentwickler Jay Kreps wählte den Namen „Kafka“, da es sich um ein System handelte, welches „für das Schreiben optimiert wurde“ und Kreps war ein Fan der Werke Franz Kafkas.
Die Hauptmotivation für die Einführung von Kafka bei LinkedIn lag darin, die bestehenden Microservices zu entkoppeln, damit sie sich freier und unabhängig voneinander entwickeln konnten. Zuvor war das Schema oder Protokoll, das für die Service-übergreifende Kommunikation verwendet wurde, die Koevolution der Services eingeschränkt. Das Infrastruktur-Team bei LinkedIn erkannte die Notwendigkeit einer erhöhten Flexibilität, um eine unabhängige Weiterentwicklung der Services zu gewährleisten. Sie entwarfen Kafka, um die Kommunikation zwischen den Services mithilfe einer asynchronen und nachrichtenbasierten Lösung zu erleichtern. Kafka musste sowohl langlebig (Nachrichten dauerhaft auf Festplatten speichern) als auch resistent gegen Netzwerk- und Knotenausfälle sein, nahezu Echtzeiteigenschaften bieten und horizontal skalieren um das Wachstum zu bewältigen. Kafka erfüllte diese Anforderungen durch die Bereitstellung eines verteilten Protokolls (siehe The Log: Was jeder Softwareentwickler über die vereinheitlichende Abstraktion von Echtzeitdaten wissen sollte).
 Bis 2011 war Kafka Open-Source, und viele Unternehmen übernahmen es massenhaft. Im Vergleich zu vorherigen ähnlichen Message-Queue- oder Pub-Sub-Abstraktionen wie RabbitMQ und HornetQ führte Kafka die folgenden wichtigen Neuerungen ein:
Bis 2011 war Kafka Open-Source, und viele Unternehmen übernahmen es massenhaft. Im Vergleich zu vorherigen ähnlichen Message-Queue- oder Pub-Sub-Abstraktionen wie RabbitMQ und HornetQ führte Kafka die folgenden wichtigen Neuerungen ein:- Die Kafka-Topics (Queues) werden partitioniert, um sie über einen Cluster von Kafka-Knoten (die sogenannten Broker) zu skalieren.
- Kafka verwendet ZooKeeper für die Cluster-Koordination, Hochverfügbarkeit und Ausfallsicherung.
- Nachrichten werden für sehr lange Zeiträume auf der Festplatte gespeichert.
- Nachrichten werden der Reihe nach gelesen.
- Die Consumer behalten ihren eigenen Status bezüglich des Offsets der zuletzt gelesenen Nachricht bei.
Dank dieser Eigenschaften muss der Producer den Status hinsichtlich der Bestätigung jeder einzelnen Nachricht nicht beibehalten. Nachrichten konnten somit in hohem Maße in das Dateisystem gestreamt werden. Da die Consumer für das Beibehalten ihres eigenen Offsets im Topic zuständig sind, konnten Updates und Ausfälle effektiv von ihnen gehandhabt werden.
Apache Storm: Dezentrales Echtzeit-Berechnungssystem
In der Zwischenzeit, im Mai 2011 , unterzeichnete Nathan Marz einen Vertrag mit Twitter zur Übernahme seiner Firma BackType. BackType war ein Unternehmen, das "Analyseprodukte entwickelte, um Unternehmen dabei zu helfen, ihre Auswirkungen auf soziale Medien sowohl historisch als auch in Echtzeit zu verstehen" [Geschichte von Apache Storm und Lessons Learned]. Eines der Vorzeigeprodukte von BackType war ein Echtzeitverarbeitungssystem namens „Storm“. Storm führte eine Abstraktion mit dem Namen „Topology“ ein, mit der Stream-Operationen in ähnlicher Weise vereinfacht wurden, wie MapReduce es für die Stapelverarbeitung getan hatte. Storm wurde unter dem Beinamen „das Hadoop der Echtzeit“ bekannt und gelangte schnell an die Spitze von GitHub und Hacker News.
Apache Flink: Zustandsorientierte Berechnungen über Daten-Streams
Flink wurde im Mai 2011 erstmals der Öffentlichkeit vorgestellt. Es geht auf ein Forschungsprojekt mit dem Namen „Stratosphere“ [http://stratosphere.eu/] zurück, das in Zusammenarbeit mit einer Handvoll deutscher Universitäten durchgeführt wurde. Stratosphere wurde mit dem Ziel entwickelt, „die Effizienz der massiv parallelen Datenverarbeitung auf Infrastructure as a Service (IaaS)-Plattformen zu verbessern“ [http://www.hpcc.unical.it/hpc2012/pdfs/kao.pdf].
Ebenso wie Storm bietet Flink ein Programmiermodell zur Beschreibung von Datenflüssen (in der Flink-Sprache als „Jobs“ bezeichnet), die eine Reihe von Streams und Transformationen enthalten. Flink enthält eine Ausführung-Engine, um den Job effektiv zu parallelisieren und ihn in einem verwalteten Cluster zu planen. Eine einmalige Eigenschaft von Flink ist, dass das Programmiermodell sowohl begrenzte als auch unbegrenzte Datenquellen unterstützt. Das bedeutet, dass nur ein minimaler Unterschied in der Syntax zwischen einem Einmal-Ausführen-Job besteht, der Daten aus einer SQL-Datenbank bezieht (zuvor wäre dies wohl ein Batch-Job gewesen) und einem Andauernd-Ausführen-Job, der mit Streaming-Daten aus einem Kafka-Thema arbeitet. Flink trat im März 2014 in das Apache-Inkubationsprojekt ein und wurde im Dezember 2014 als Top-Level-Projekt akzeptiert.
Im Februar 2013 wurde die Alpha-Version von Spark Streaming mit Spark 0.7.0 veröffentlicht. Im September 2013 hat das LinkedIn-Team mit diesem Beitrag sein Stream-Processing-Framework „Samza“ veröffentlicht.
Im Mai 2014 wurde Spark 1.0.0 veröffentlicht und mit dieser Version wurde Spark SQL erstmalig eingeführt. Obwohl die aktuelle Spark-Version zu diesem Zeitpunkt nur eine Streaming-Funktion bot, die eine Datenquelle in „Micro-Batches“ aufteilte, wurden mit dieser Version die Voraussetzungen für die Ausführung von SQL-Abfragen als Streaming-Anwendungen geschaffen.
Apache Beam: Ein einheitliches Programmiermodell für Batch- und Streaming-Jobs
Im Jahr 2015 veröffentlichte ein Team von Google-Ingenieuren ein Papier mit dem Titel The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Eine Implementierung des Dataflow-Modells wurde 2014 auf der Google Cloud Platform kommerziell verfügbar gemacht. Sowohl das Core-SDK dieser Arbeit als auch mehrere I/O-Konnektoren und ein lokaler Runner wurden an Apache gespendet und im Juni 2016 in die erste Version von Apache Beam umgemünzt.
Einer der Schwerpunkte des Dataflow-Modells (und von Apache Beam) basiert darauf, dass die Darstellung der Pipeline unabhängig von der Wahl der Ausführungs-Engine abstrahiert wird. Zum Zeitpunkt des Schreibens kann Beam denselben Pipeline-Code erstellen, um Flink, Spark, Samza, GearPump, Google Cloud Dataflow und Apex anzusprechen. Infolgedessen haben Benutzer die Möglichkeit, die Ausführungs-Engine zu einem späteren Zeitpunkt weiter zu entwickeln, ohne die Implementierung des Jobs abzuändern. Zum Testen und Entwickeln in der lokalen Umgebung steht außerdem eine „Direct Runner“-Ausführungs-Engine zur Verfügung.
2016 führte das Flink-Team Flink SQL ein. Kafka SQL wurde im August 2017 angekündigt, und im Mai 2019 lieferte eine Gruppe von Ingenieuren von Apache Beam, Apache Calcite und Apache Flink "One SQL to Rule Them All: An Efficient and Syntactically Idiomatic Approach to Management of Streams and Tables" für ein einheitliches Streaming-SQL.
Ein Blick in die Zukunft
Die Tools, die den Softwarearchitekten für das Design der Daten-Pipeline zur Verfügung stehen, entwickeln sich mit zunehmender Geschwindigkeit weiter. Wir sehen, dass Workflow-Engines wie Airflow und Prefect Systeme wie Dask integrieren, um es Benutzern zu ermöglichen, massive Machine Learning-Workloads für den Cluster zu parallelisieren und zu planen. Aufstrebende Konkurrenten wie Apache Pulsar und Pravega konkurrieren mit Kafka, um die Speicherabstraktion des Streams zu übernehmen. Wir sehen auch Projekte wie Dagster, Kafka Connect und Siddhi , die bestehende Komponenten integrieren und neuartige Ansätze zur Visualisierung und Gestaltung der Datenpipeline liefern. Die rasante Weiterentwicklung der Technologien in diesen Bereichen macht die Entwicklung datenintensiver Anwendungen gerade jetzt besonders spannend.
Wenn die Arbeit mit dieser Art von Technologien für Sie interessant ist, empfehlen wir Ihnen, sich mit uns in Verbindung zu setzen! Wir stellen in mehreren Engineering-Rollen und an mehreren Standorten ein.

Den Blog durchsuchen

Abonnieren Sie den Barracuda-Blog.
Melden Sie sich an, um aktuelle Bedrohungsinformationen, Branchenkommentare und mehr zu erhalten.
