
Hochgradig skalierbare Ereignisprotokollierung auf AWS
Die meisten Anwendungen generieren Konfigurations- und Zugriffsereignisse. Administratoren müssen Aufschluss über diese Ereignisse erhalten können. Der Barracuda Email Security Service bietet Transparenz und Aufschluss zu vielen solchen Ereignissen, um Administratoren die Feinabstimmung sowie das Verständnis des Systems zu erleichtern. So können sie z. B. erfahren, wer sich wann bei einem Konto angemeldet hat — oder wer die Konfiguration einer bestimmten Richtlinie hinzugefügt, geändert oder gelöscht hat.Bei der Erstellung eines solchen dezentralen und durchsuchbaren Systems kommen viele Fragen auf, z. B.:
- Wie soll man alle diese Protokolle von all diesen Anwendungen, Services und Geräten aus an einem zentralen Ort aufzeichnen?
- Welches Standardformat sollen die Protokolldateien aufweisen?
- Wie lange sollen diese Protokolle aufbewahrt werden?
- Wie soll man Ereignisse von verschiedenen Anwendungen zueinander in Beziehung setzen?
- Wie kann man einen einfachen, raschen Suchmechanismus über eine Benutzeroberfläche für den Administrator zur Verfügung stellen?
- Wie kann man diese Protokolle über ein API verfügbar machen?
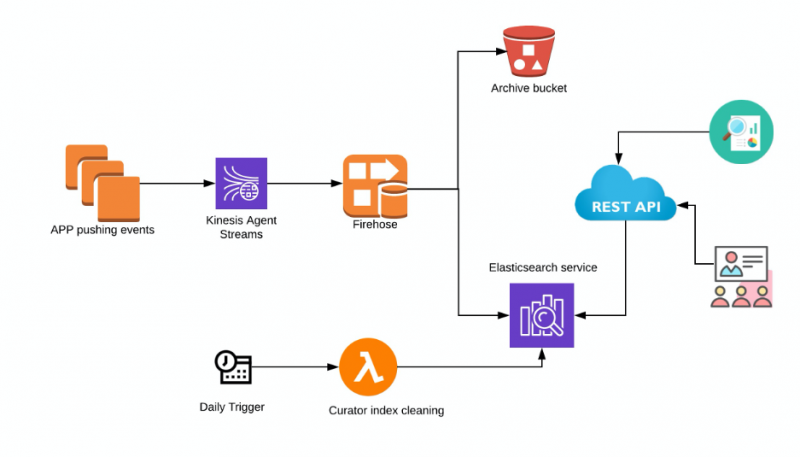
An dieser Architektur beteiligte Komponenten
- Kinesis Agent - Amazon Kinesis Agent ist eine eigenständige Java-Softwareanwendung, die eine einfache Möglichkeit bietet, Daten zu sammeln und an Kinesis Data Firehose zu senden. Der Agent überwacht kontinuierlich Ereignisprotokolldateien auf den EC2-Linux-Instanzen und sendet sie an den konfigurierten Kinesis Data Firehose-Auslieferungsstream. Der Agent ist für Dateirotation, Checkpointing und erneutes Versuchen nach Fehlschlägen verantwortlich. Er stellt alle Daten auf zuverlässige, schnelle und unkomplizierte Art und Weise bereit. Hinweis: Wenn es sich bei der Anwendung, die Daten in Kinesis Firehose schreiben soll, um einen Fargate-Container handelt, benötigen Sie einen Fluentd-Container. Dieser Artikel konzentriert sich jedoch auf Anwendungen, die auf Amazon EC2-Instances ausgeführt werden.
- Kinesis Data Firehose – Die Direct-Put-Methode von Amazon Kinesis Data Firehose kann die Daten im JSON-Format in Elasticsearch schreiben. So werden keine Daten im Stream gespeichert.
- S3 — Ein S3-Bucket kann verwendet werden, um entweder alle Datensätze oder Datensätze, die nicht an Elasticsearch geliefert werden können, zu sichern. Lifecycle-Richtlinien können auch für eine automatische Archivierung von Protokollen konfiguriert werden.
- Elasticsearch — Elasticsearch wird von Amazon gehostet. Es kann der Zugriff auf Kibana aktiviert werden, um die Protokolle zu Debugging-Zwecken abzufragen und zu durchsuchen.
- Curator — AWS empfiehlt die Verwendung von Lambda und Curator zur Verwaltung der Indizes und Snapshots des Elasticsearch-Clusters. AWS hat weitere Details und Beispielimplementierung, die Sie hier finden können.
- REST API-Schnittstelle – Sie können eine API als Abstraktion für Elasticsearch erstellen, die sich gut in die Benutzeroberfläche integriert. API-gestützte Microservice-Architekturen sind nachweislich in vielerlei Hinsicht die besten, z. B. in Bezug auf Sicherheit, Compliance und Integration mit anderen Services.
Skalierung
- Kinesis Data Firehose: Standardmäßig können Firehose-Lieferströme auf bis zu 1.000 Datensätze/s oder 1 MiB/s für den Osten der USA (Ohio) skaliert werden. Das ist eine weiche Grenze und sie kann auf bis zu 10.000 Datensätze/Sek. erhöht werden. Diese Skalierungen sind abhängig von der Region.
- Elasticsearch: Der Elasticsearch-Cluster lässt sich sowohl im Hinblick auf Speicherplatz als auch auf Rechenleistung auf AWS skalieren. Auch Versionsupgrades sind möglich. Amazon ES verwendet beim Aktualisieren von Domains einen Bereitstellungsprozess vom Typ „blau/grün“. Somit kann die Anzahl von Nodes in dem Cluster vorübergehend ansteigen, während Ihre Änderungen übernommen werden.
Vorteile dieser Architektur
- Die Pipeline-Architektur wird effektiv vollständig verwaltet und überzeugt mit einem sehr geringen Wartungsaufwand.
- Im Falle eines Fehlschlagens des Elasticsearch-Clusters kann Kinesis Firehose Datensätze bis zu 24 Stunden lang aufbewahren. Außerdem werden Datensätze, die nicht zugestellt werden können, ebenfalls in S3 gesichert.
Mit diesen verfügbaren Optionen ist die Wahrscheinlichkeit von Datenverlusten gering.
- Es ist eine detaillierte Zugangskontrolle für die Kibana- und Elasticsearch-API über IAM-Richtlinien möglich.
Nachteile
- Die Preisgestaltung muss sorgfältig durchdacht und überwacht werden. Die Kinesis Data Firehose kann mühelos umfangreiche Dateneinspeisungen bewältigen. Wenn ein „wild gewordener“ Service auf einmal große Datenmengen protokolliert, liefert Kinesis Data Firehose sie ohne zu Fragen aus. Dies kann zu hohen Kosten führen.
- Die Integration von Kinesis Data Firehose mit Elasticsearch wird nur für Nicht-VPC-Elasticsearch-Cluster unterstützt.
- Die Kinesis Data Firehose kann derzeit keine Protokolle für Elasticsearch-Cluster bereitstellen, die nicht von AWS gehostet werden. Wenn Sie Elasticsearch-Cluster selbst hosten möchten, funktioniert dieses Setup nicht.
Fazit
Wenn Sie nach einer Lösung suchen, die vollständig verwaltet ist und sich (meist) ohne Eingreifen skalieren lässt, wäre dies eine gute Option. Das automatische Backup auf S3 mit Lifecycle-Richtlinien löst auch ganz unkompliziert das Problem hinsichtlich der Aufbewahrung und Archivierung von Protokollen.






Abonnieren Sie den Barracuda-Blog.
Melden Sie sich an, um aktuelle Bedrohungsinformationen, Branchenkommentare und mehr zu erhalten.
