
Kleine Sprachmodelle bringen große Geschäftsvorteile
Eine kürzlich durchgeführte Umfrage hat ergeben, dass die meisten globalen IT-Führungskräfte befürchten, dass ihre Unternehmen „abgehängt“ werden, wenn sie keine künstliche Intelligenz (KI) einführen. Mehr als die Hälfte dieser Führungskräfte geben außerdem an, dass der Druck der Kunden eine entscheidende Triebkraft für die Einführung von KI ist und dass KI entscheidend für die Steigerung der Effizienz und des Kundenservice im Unternehmen ist. Die meisten Unternehmen sehen die Einführung von KI als notwendig an, um ihre Wettbewerbsfähigkeit zu wahren.
Trotz der Begeisterung haben viele Unternehmen Bedenken hinsichtlich der Implementierungskosten, des möglichen Missbrauchs durch Mitarbeiter und potenzieller Compliance-Probleme. Der im August 2024 veröffentlichte „State of Intelligent Automation Report“ von ABBY zeigt, wie diese Bedenken bei den Umfrageteilnehmern eingestuft werden.
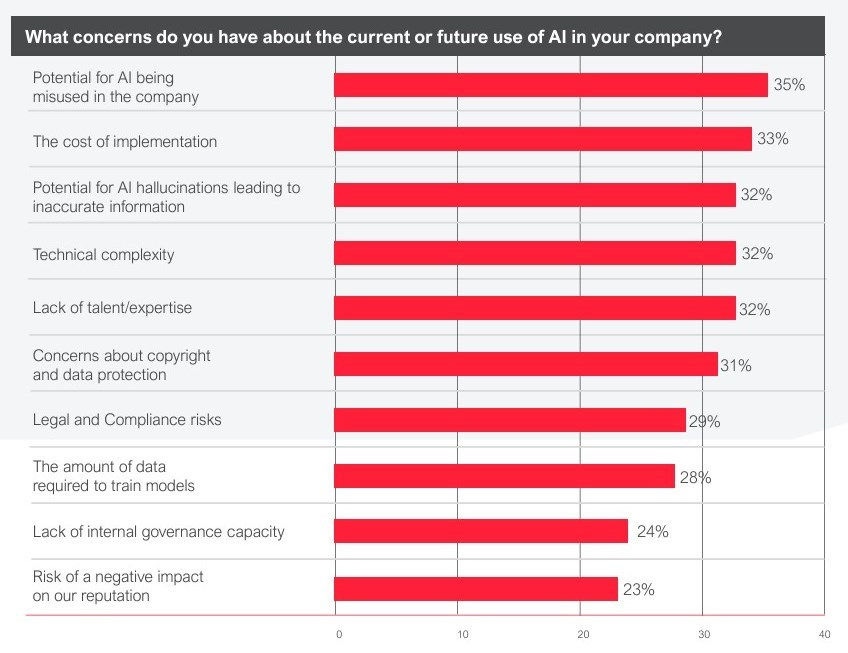
Verschiedene Bedenken über den aktuellen und zukünftigen Einsatz von KI, August 2024 State of Intelligent Automation Report, ABBY
Der Bericht hebt auch hervor, dass IT-Führungskräfte ein hohes Maß an Vertrauen kleinen Sprachmodellen (Small Language Models, SLMs) im Vergleich zu anderen Arten von KI entgegenbringen. Ein wichtiges Ergebnis ist, dass der Fertigungssektor mit 92 % das höchste Vertrauen in SLMs aufweist, dicht gefolgt von Finanzdienstleistungen und IT mit 9 1%.
Was ist ein kleines Sprachmodell?
Ein kleines Sprachmodell (SLM) ist ein neuronales Netzwerk, das entwickelt wurde, um Inhalte in natürlicher Sprache zu generieren, jedoch mit weniger Parametern als große Sprachmodelle (LLMs). Wir werden auf die Bedeutung von Parametern zurückkommen, aber hier ist ein kurzer Blick auf die Unterschiede zwischen SLMs und LLMs:
Zweck/Anwendungsfälle:
- SLMs: Domänenspezifische Aufgaben, Edge Computing, ressourcenbeschränkte Umgebungen. Das Training konzentriert sich auf domänenspezifische Datensätze. SLMs bieten häufig schnellere Antworten/Schlussfolgerungen und geringere Latenz. Domänen- und Endpunktbereitstellungen eignen sich besser für den Umgang mit vertraulichen Daten, da die Daten lokal bleiben.
- LLMs: Allgemeine Sprachaufgaben, komplexes Denken. Das Training basiert auf umfangreichen, vielfältigen Datensätzen, die ihnen ein breiteres Wissen und mehr Flexibilität bieten. Große Sprachmodelle sind auch besser für komplexe Aufgaben geeignet als die schlankeren, domänenspezifischen SLMs, erfordern jedoch möglicherweise, dass sensible Daten zur Verarbeitung in die Cloud gesendet werden.
Betriebsanforderungen:
- SLMs: Geringere Rechenleistung, weniger Speicher und geeignet für die Bereitstellung vor Ort oder auf Edge-Geräten. SLMs sind fast immer kosteneffizienter zu trainieren und im Produktionsbetrieb zu nutzen.
- LLMs: Hohe Rechenleistung, großer Speicherbedarf und höhere Betriebs- und Trainingskosten.
Nun zu den Parametern. Dabei handelt es sich um numerische Werte, die bestimmen, wie ein SLM oder LLM Eingaben verarbeitet und Ausgaben generiert. Es gibt Ausreißer, aber SLMs haben in der Regel weniger als 100 Millionen Parameter, wohingegen LLMs normalerweise Milliarden oder Billionen haben. Eine einfache Möglichkeit, die Beziehung zwischen einem Parameter und einem Sprachmodell zu veranschaulichen, ist das Beispiel einer Bibliothek. Eine medizinische oder juristische Bibliothek verfügt vielleicht über Hunderte oder Tausende von Büchern, die für ihr Fachgebiet relevant sind. Eine große Bibliothek mit Ressourcen zu jedem Thema wird mehr Bücher (Parameter) haben, die aber nicht alle für Ihre Interessen relevant sind. Die größere Bibliothek erfordert mehr Ressourcen, kann aber auch Informationen zu mehr Themen liefern.
Die Parameter sind das 'Wissen', das das Sprachmodell während seines Trainings erlernt hat. Sollte Ihr Unternehmen KI-Technologie benötigen, die eine begrenzte Anzahl von Aufgaben sehr gut ausführt, könnte das kleine Sprachmodell mit weniger Parametern Ihren Anforderungen entsprechen.
Datensicherheit und Transparenz
Da SLMs mit begrenzten Daten trainiert werden und auf Edge-Geräten eingesetzt werden können, sind diese Modelle möglicherweise für Unternehmen attraktiver, denen Sicherheit und Compliance wichtig sind. Die Daten werden lokal verarbeitet, was die Prüfung, Steuerung und Überwachung der Entscheidungsprozesse des Modells erleichtert. Das regulatorische Umfeld für KI verändert sich rasant, und viele Regierungen haben bereits Transparenzvorschriften eingeführt. Zum Beispiel:
Die Europäische Union (EU) verlangt im Rahmen des AI Act (2024), dass Nutzer informiert werden müssen, wenn sie in bestimmten Anwendungen mit KI-Systemen interagieren. Es wird auch von Unternehmen, die Hochrisiko-KI-Systeme betreiben, verlangt, eine Dokumentation über bestimmte Aspekte dieser Systeme bereitzustellen.
In den Vereinigten Staaten (USA) gehören Utah, Colorado und Kalifornien zu den ersten Bundesstaaten, die Vorschriften zur Transparenz von KI-Systemen und deren Nutzung entwickelt haben. Diese Vorschriften können die Offenlegung des Einsatzes von KI, Richtlinien für das Risikomanagement und den Schutz vor Verzerrungen in den KI-Systemen verlangen.
Technologieanbieter und Verbände haben ihre eigenen Richtlinien zur KI-Governance und Ethik veröffentlicht, in denen Transparenz häufig als grundlegendes Element für die Akzeptanz von KI betrachtet wird.
Dieser Drang nach Transparenz löst bei Entwicklern und Unternehmen, die mit KI arbeiten, eine andere Art von Besorgnis aus. Proprietäre kleinere oder größere Sprachmodelle (SLMs bzw. LLMs) gelten oft als geistiges Eigentum (Intellectual Property, IP) und als Wettbewerbsvorteil. Die Unternehmen wollen die Details dieser Assets normalerweise nicht offenlegen. Es besteht auch ein berechtigtes Sicherheitsproblem, wenn zu viele Informationen über ein Sprachmodell bereitgestellt werden. Bedrohungsakteure könnten diese Informationen verwenden, um das Modell anzugreifen oder zu missbrauchen.
Weitere Bedenken im Zusammenhang mit der Regulierung von Transparenz ergeben sich aus der Komplexität der Modelle, die es schwierig macht, die erforderlichen Informationen Laien ohne technischen Hintergrund zu vermitteln. Diese Komplexität und das Fehlen allgemein anerkannter Standards für KI lassen viele befürchten, dass die Compliance mit Transparenzvorschriften zu einem Hindernis für Innovationen und Einsätze werden könnte.
Edge-Computing
Edge-Computing wächst in rasantem Tempo, vor allem aufgrund von Industrie 4.0-Initiativen und der Verbreitung von mit dem Internet verbundenen Geräten und Steuerungen in den Bereichen Fertigung, Energie und Transport. Fortschritte in der 5G-Technologie und die Vorteile der Echtzeitverarbeitung auf Remote-Geräten haben ebenfalls zu diesem Wachstum beigetragen. Die COVID-19-Pandemie beschleunigte zwar die Einführung von Edge-Computing, um Remote-Arbeit zu unterstützen, jedoch ist dieser Faktor weitaus weniger signifikant als das Wachstum des Internet of Things (IoT) und des Industrial Internet of Things (IIoT).
Kleine Sprachmodelle sind nahezu perfekte Lösungen für Edge-Computing-Geräte, und die Edge-KI wird ständig verbessert. Dennoch gibt es immer noch einige Einschränkungen zu berücksichtigen. SLMs für Edge-Geräte erfordern oft häufigere Updates und Feinabstimmungen, was bei Geräten mit begrenzter Konnektivität eine Herausforderung darstellen kann. Zudem stoßen SLMs schneller an ihre Leistungsgrenzen, wenn die Anforderungen an die Datenverarbeitung steigen. Und obwohl SLMs in der Regel einen höheren Datenschutz bieten, können Daten, die von Edge-Geräten in die Cloud übertragen werden, potenziellen Risiken ausgesetzt sein.
Kontinuierliches Wachstum für SLMs
Es besteht kein Zweifel, dass die Einführung kleiner Sprachmodelle in Unternehmen weiter zunehmen wird, und das wird nicht nur durch Edge-KI und IIoT vorangetrieben. Automatisierung im Kundenservice, maschinelle Übersetzung, Sentiment-Analyse und andere spezifische Anwendungsfälle tragen ebenfalls zu diesem Wachstum bei. Microsoft, Google und andere KI-Anbieter sind der Meinung, dass SLMs „genauere Ergebnisse zu wesentlich geringeren Kosten“ bieten und einen Wandel hin zu einem Portfolio von Modellen ermöglichen, mit dem Unternehmen die für sie am besten geeigneten Modelle auswählen können.
Wenn Sie mehr über SLMs und ihre Funktionsweise erfahren möchten, können diese Websites hilfreich sein:
IBM: Sind größere Sprachmodelle immer besser?
Salesforce: Tiny Titans: Wie kleine Sprachmodelle LLMs für weniger Aufwand übertreffen
HatchWorksAI: Wie Sie kleine Sprachmodelle für Nischenbedürfnisse im Jahr 2024 nutzen können
Microsoft: Klein, aber oho: Die Phi-3-Sprachmodelle mit großem Potenzial






Abonnieren Sie den Barracuda-Blog.
Melden Sie sich an, um aktuelle Bedrohungsinformationen, Branchenkommentare und mehr zu erhalten.
